I/O redirection in bash
Posted by David Zaslavsky on — CommentsBash, the shell commonly found on modern Linux systems, has a well-deserved reputation for being a tremendously complicated piece of software. The man page is more than three thousand lines long — what for most other programs would be the “pocket reference manual” is in this case more like a hundred-page book! But it’s everywhere, so if you want to do shell scripting, you have to know Bash. (To be fair, other shells can be even weirder) I’ve been working with this shell for a long time, and over the years I’ve come to terms with most of its wacky features: parameter expansion, quoting, variable substitution, job control, arrays, here strings, arithmetic evaluation, signal handling, and more. But I have never been able to understand I/O redirection.
Until now.
Now, I’m not talking about the basics. Of course I knew how to use the simple examples; for instance, I learned early on that
command >output.txt >errput.txt
means that anything the command prints to its standard output stream winds up in output.txt and anything it prints to its standard error winds up in errput.txt. I know that you can “merge” standard output and standard error so they both wind up going to the same place, like
command >&allput.txt
or
command >allput.txt 2>&1
But what’s really going on behind the scenes?
When you run a command in Bash, the process gets initialized with a set of file descriptors that are inherited from the shell’s process. Think of this as wiring a switchboard.
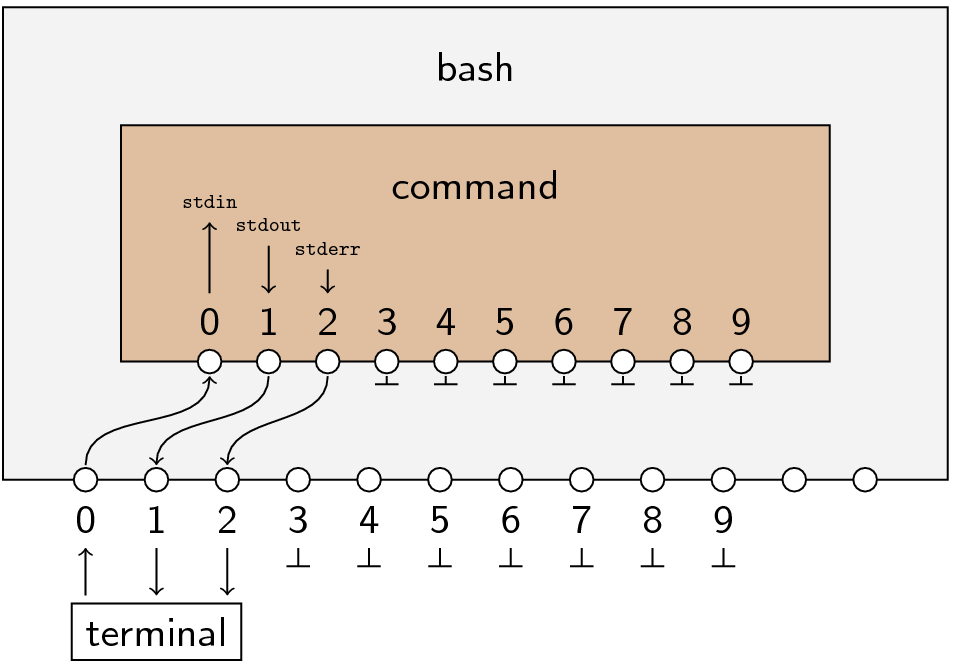
Let’s consider this example first:
command >allput.txt 2>&1
Bash evaluates the command line from left to right. First, of course, it reads the name of the command and figures out what program to run. Then it runs into the first redirection, >allput.txt, which is equivalent to 1>allput.txt. How shall we interpret this? First of all, the number on the left of the > indicates the number of the file descriptor to modify. In this case it’s 1, so Bash starts by breaking whatever connection was previously attached to the process’s file descriptor 1. 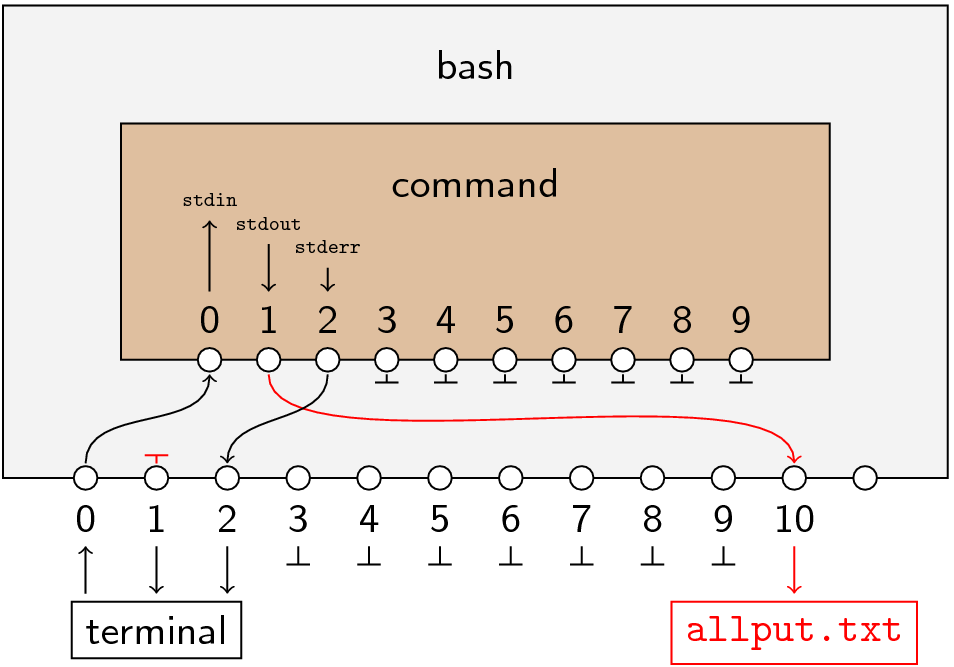 Whatever is on the right of the
Whatever is on the right of the > indicates what should replace that connection; here it’s a file. (As the picture shows, Bash has to allocate one of its own file descriptors to open the file, but that isn’t important.)
After parsing that, Bash reaches 2>&1. Again, we start on the left of the > and see that this redirection modifies file descriptor 2. So Bash breaks the connection to file descriptor 2. This time, on the right is &1 which means “whatever file descriptor 1 is connected to,” which is the file allput.txt. 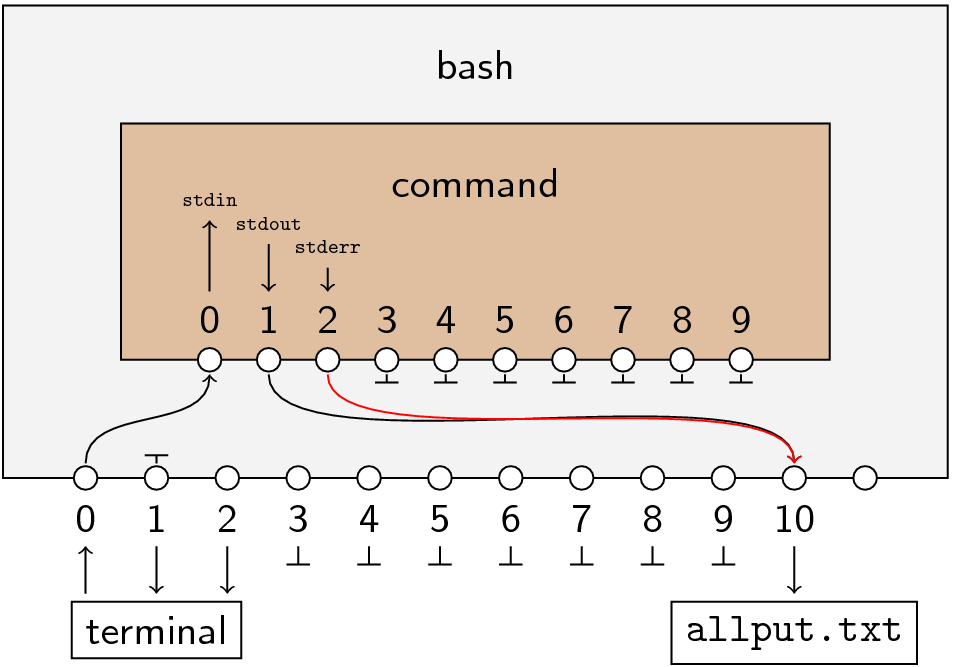 So the net result is that file descriptors 1 and 2 wind up emitting to the file.
So the net result is that file descriptors 1 and 2 wind up emitting to the file.
It’s important to remember that when you talk about “standard output” and “standard error,” that always refers to file descriptors 1 and 2 of the process, respectively. Think about how programs are written: when you want to print something to standard output:
fprintf(1, "something");
you send it to file descriptor 1. Period. There’s a tendency to think of “standard output” and “standard error” as destinations that the process’s file descriptors can be connected to, but that’s not correct and it can lead to years of confusion.
Once you figure this out, it’s easy to understand why, for example,
command 2>&1 >allput.txt
doesn’t work. Putting the redirections in the wrong order makes Bash first connect the process’s file descriptor 2 to where its file descriptor 1 is connected — the terminal — and then connect file descriptor 1 to the file. Understanding this is practically a rite of passage for all Bash scripters, and even Linux users in general because it comes up so often.