Introducing pwait
Posted by David Zaslavsky on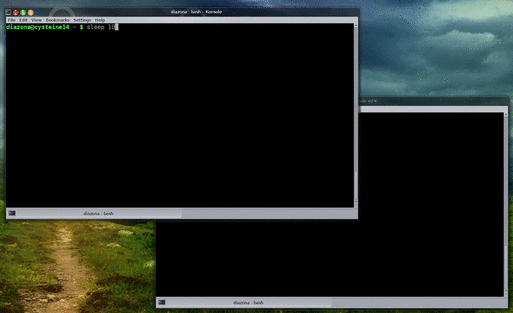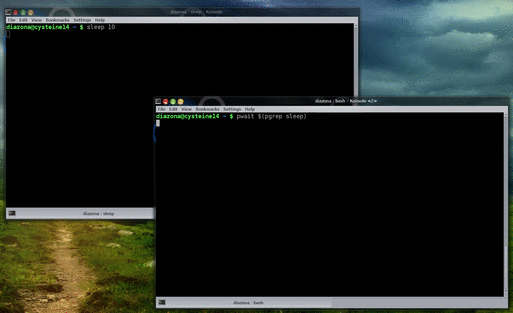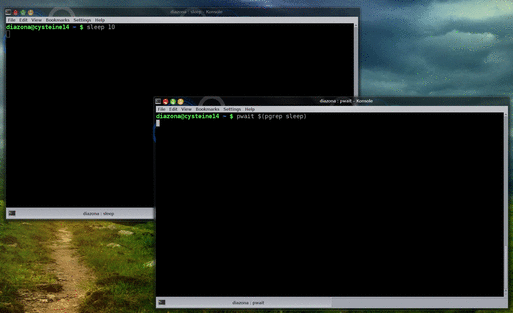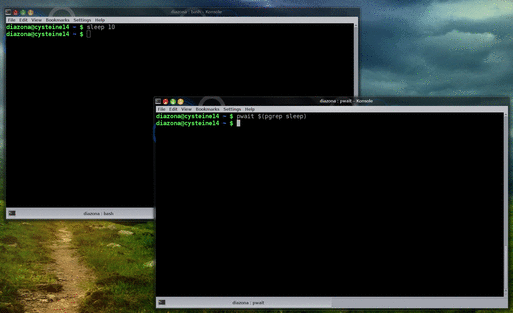
Today I’m announcing pwait, a little program I wrote to wait for another program to finish and return its exit code. Download it from Github and read on…
Why pwait?
Because I was procrastinating one day and felt like doing some systems programming.
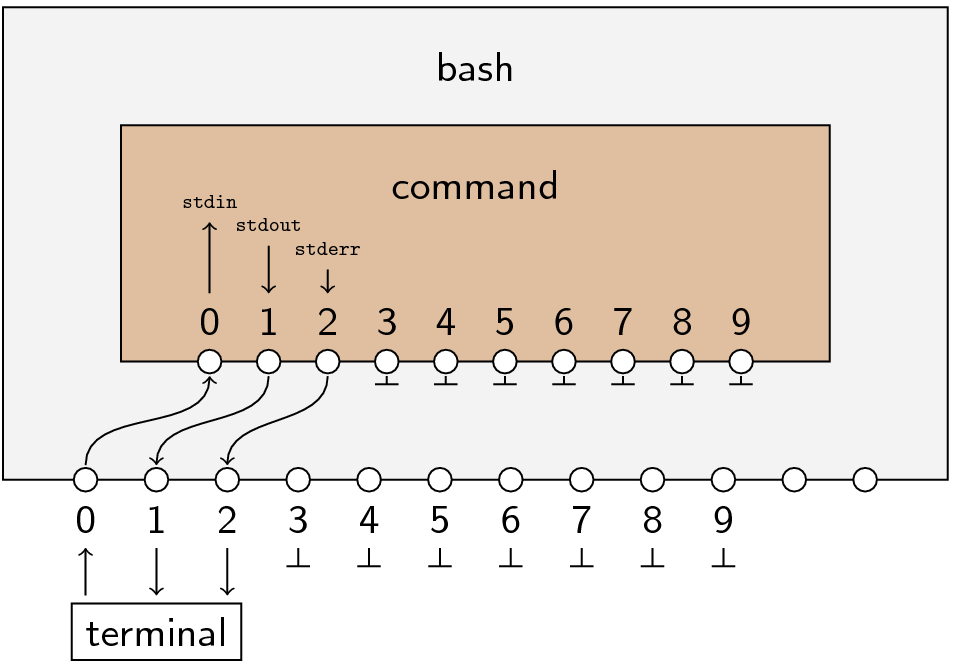
Seriously though. Sometimes you need to run one program after another one finishes. For example, you might be running a calculation and then you need to run the data analysis script afterwards, but only if the calculation finished successfully. The easy way to do this is
run_calculation && analyze_data
(sorry to readers who don’t know UNIX shell syntax, but then again the program I’m introducing is useless to you anyway).
Which is fine if you plan for this before you run the calculation in the first place, but sometimes you already started the calculation, and it’s been running for 3 hours and you don’t want to stop it and lose all that progress. The easy way to do this is to hit Ctrl+Z (or some equivalent; it depends on your terminal) to suspend the calculation, and then run
fg && analyze_data
which will resume it and run the analysis script afterwards.
Which is …